There’s a version of the smart building story where AI fixes everything. Plug sensors into a platform, add some machine learning, and the building runs itself. Energy drops, comfort improves, maintenance gets predicted before anything breaks.
It’s a good story. It also skips the part where the sensors are wrong.
The dirty secret of building analytics
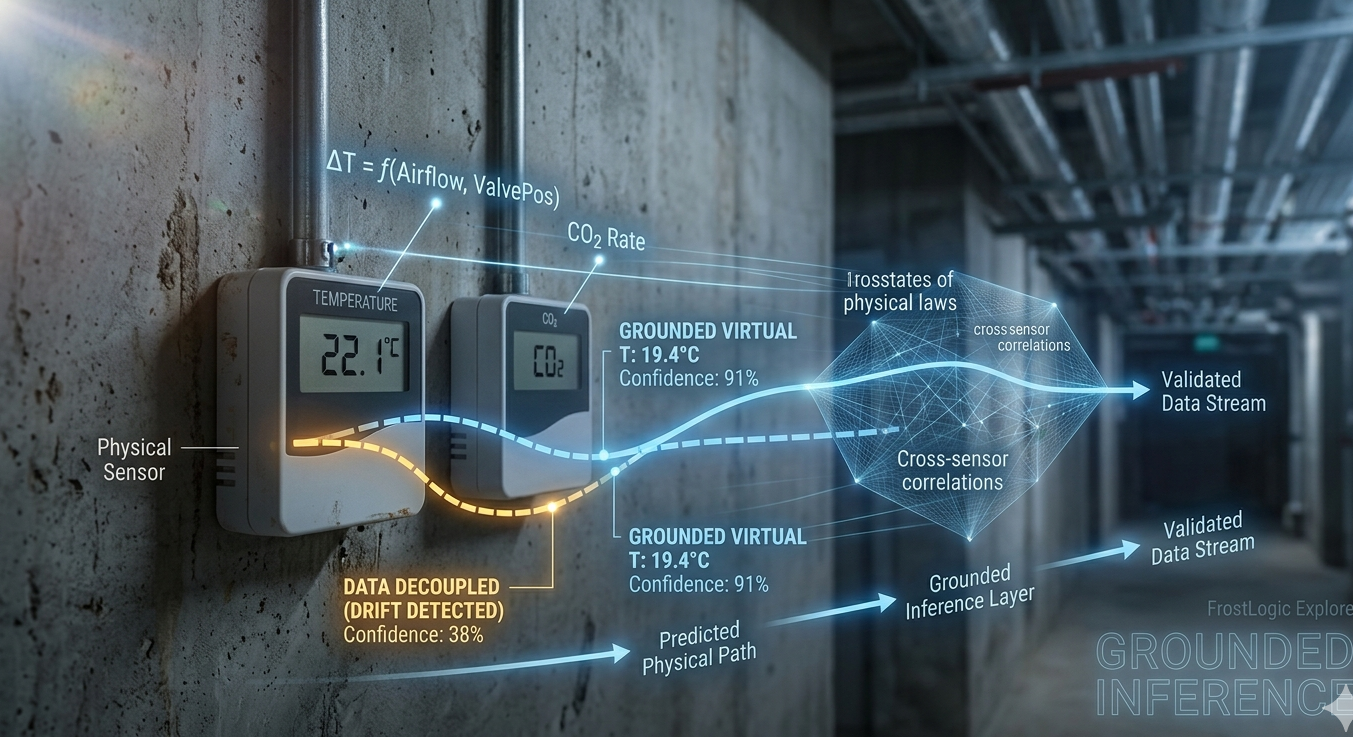
A temperature sensor on Floor 4 reads 22.1°C. It’s been reading 22.1°C for three days straight. In a conference room that seats 40 people and sits empty half the day, that number should be moving. It isn’t. The sensor is stuck.
Most analytics platforms will happily report that Floor 4 is maintaining a perfect 22.1°C. The anomaly detection won’t flag it because there’s no anomaly in the reading itself. The energy optimization will use it as a valid input. The compliance report will mark indoor thermal comfort as “pass.”
Everything downstream of that sensor is now quietly wrong.
This is the data trust problem. It’s not exotic. It’s not theoretical. In any building with more than a few hundred sensors, some percentage of them are drifting, stuck, intermittent, or reporting values that don’t match physical reality. Facilities teams typically discover sensor issues only after a comfort complaint or an energy bill that doesn’t add up. By then, months of data may be compromised.
Why most AI doesn’t catch it
Standard anomaly detection looks for values that fall outside expected ranges. A temperature reading of 85°C in an office? Flagged. A humidity sensor reporting negative values? Flagged. These are easy.
The hard problems are subtler. A sensor that drifts 0.3°C per month. An airflow measurement that’s consistently 15% low because the sensor element is dirty. An energy meter that drops offline for two hours every night and backfills with interpolated data. A CO2 sensor that tracks perfectly with occupancy in winter but decouples in summer because the HVAC switchover changes the air path.
Generic ML models trained on the sensor data itself can’t reliably distinguish these patterns from normal building behavior. They lack context. They don’t know that a supply air temperature of 18°C is reasonable at 3 AM in January but suspicious at 3 PM in July. They don’t know that AHU-3 and AHU-7 serve the same zone and their readings should correlate within a certain band.
The AI doesn’t understand the building. It just sees numbers.
What changes when AI understands the physics
FrostLogic Explore approaches this differently. The system’s intelligence layer is grounded by a proprietary world model that encodes the physical relationships within a building. Supply and return air temperatures on the same air handling unit should follow a predictable thermodynamic relationship. CO2 levels in an occupied zone should respond to ventilation rates with a specific lag. Energy consumption and outdoor temperature are correlated, but the shape of that correlation depends on whether the building is in heating or cooling mode. The world model encodes all of this.
The result is that sensor validation stops being a statistical exercise and becomes a physics-informed one. When a sensor starts drifting, Explore doesn’t just notice that the value is unusual. It notices that the value has decoupled from the physical relationships it should be part of. The drift might be small enough to pass every statistical test, but the disagreement with the world model catches it.
We call this approach grounded inference. Every insight the system produces is anchored to the physical reality of the building, not just to what the data says. When the data and the physics disagree, that disagreement is the signal.
Confidence bands, not false certainty
One of the more honest things a building AI can do is tell you how much to trust its own outputs.
Explore assigns confidence scores to its analytics based on the underlying data quality. If three of the five sensors feeding a zone-level energy estimate are showing signs of drift, the confidence band on that estimate widens. The forecast still runs, but it comes with a visible qualifier: this number is based on degraded inputs.
This is a departure from how most platforms work. The standard approach is to produce a clean number and let the user assume it’s reliable. In reality, data quality in a building fluctuates constantly. Sensors degrade, communication links drop, firmware updates change calibration. A system that doesn’t account for this is giving you precision without accuracy.
Explore also generates virtual sensors, calculated metrics derived from the relationships between existing sensors that can fill gaps when a physical sensor fails or becomes unreliable. If a return air temperature sensor goes offline, the system can estimate the value from supply air temperature, zone temperatures, and airflow rates, flagging it as a virtual reading so the operations team knows the provenance.
Why this matters beyond the dashboard
Unreliable sensor data doesn’t just produce bad analytics. It cascades.
A drifting temperature sensor tells the BMS the zone is too warm. The BMS opens the cooling valve. The cooling plant works harder. The energy bill goes up. The ESG report shows increased consumption. The certification audit flags a negative trend. The operations team spends two weeks investigating an “energy problem” that is actually a sensor problem.
Every layer of building intelligence, from anomaly detection to compliance tracking to energy forecasting, inherits the quality of the data beneath it. If the AI layer doesn’t validate its own inputs, it becomes a confidence multiplier on bad data. The outputs look authoritative. The dashboards are green. And the building is slowly, invisibly, running wrong.
The baseline for 2026
The EU AI Act, which began enforcement in 2025, requires that AI systems used in decision-making contexts maintain data quality and transparency about their limitations. For building AI that informs energy management, compliance reporting, or maintenance scheduling, this isn’t abstract regulation. It’s a direct requirement to demonstrate that the data feeding the model is trustworthy and that the model’s outputs carry appropriate caveats.
The industry is catching up. “AI for data trust” is becoming a standard expectation: sensor drift scoring, stuck-value detection, missing data identification, and confidence bands on every output. These aren’t premium features. They’re the minimum for an AI system that’s honest about what it knows and what it doesn’t.
Buildings are physical systems with physical constraints. The AI that understands them should be, too.
Curious where your building’s data quality stands? Try our free Building Intelligence Score assessment.
FrostLogic Explore is an AI-powered sensor intelligence platform that grounds its analytics in the physical reality of your building. Learn more about Sensor Intelligence or request a demo.
FrostLogic Explore brings sensor intelligence, scenario simulation, and grounded-inference AI to commercial and industrial buildings. Learn more about Sensor Intelligence or request a demo.
Curious how this would look on your building?
Book a 20-minute walkthrough.
Sensor Intelligence on a sample of your data. Senior engineer on the call.
